Documentación Esta documentación se aplica solo a iceScrum v7.
Para el antiguo iceScrum R6, lea la documentación o migrate.
-
Instalar o Actualizar
-
Para empezar
-
Características principales
Apps & integraciones
Neatro
Companion
MURAL
Microsoft Teams
Discord
iObeya
Zoom
Google Hangouts Meet
Jamboard by Google
Miro
Jitsi Meet
Mattermost
Custom project dashboard
Agile KPIs
Webhooks
Forecast
Agile fortune
SAML Authentication
Labels
Share
Zapier
Story workflow
FeatureMap
Time tracking
Diagrams & mockups
Epic stories
Portfolio
Roadmap del proyecto
Toolbox
Autenticación externa
Integración continua
Almacenamiento en la nube
Capacidad del equipo
Bug trackers
LDAP / Active Directory
Slack
Administración de proyecto
User administration
Server administration
Git & SVN
Exportación de datos
Mood
Importación Excel
Responsable de tarea
Voto de historia
Plantilla de historia
Apps & integraciones
Pilas personalizadas
-
Migración
-



Sincronice automáticamente los datos de su proyecto entre su bug/ticket tracker y iceScrum.
![]()
![]()
![]()
![]()
![]()
Esta integración es bidireccional: puede importar problemas desde su bug tracker para crear historias iceScrum y puede actualizar automáticamente los problemas en su bug tracker cuando se actualicen las historias correspondientes.
Principios
La integración de bug tracker en iceScrum se divide en varias Apps, una para cada bug tracker con la que iceScrum está integrada. La mayor parte de la lógica de integración se comparte entre ellos, por eso la documentación está unificada.
Hay 4 pasos para definir la integración con un bug tracker:
- Habilitar la App,
- Configurar la conexión en la configuración de su proyecto,
- Importar problemas gracias a las reglas de importación (bug tracker -> iceScrum),
- Actualizar los problemas según las actualizaciones de la historia gracias a las reglas de sincronización (iceScrum -> bug tracker).
Tenga en cuenta que actualmente no hay forma de actualizar o eliminar una historia cuando se actualiza o se cierra el problema correspondiente.
Please note that there is currently no way to update or delete a story when the corresponding issue is updated or closed.
Los bug trackers actualmente disponibles son:
- Mantis BT: 1.2.15 y superior (2.x es compatible),
- Bugzilla: 3.6 y superior con el plugin XML-RPC instalado , consulte la sección dedicada,
- Trac: 1.0.1 y superior con el plugin XML-RPC instalado , consulte la sección dedicada,
- Redmine: 2.6.2 y superior, consulte la sección dedicada.
- Jira: 6.2.7 y superior, consulte la sección dedicada.
Desarrollamos esta integración como parte de nuestro servicio de patrocinio que permite a las empresas dar la máxima prioridad al desarrollo de una característica de su elección. Queremos agradecer a nuestros clientes que patrocinaron las integraciones actualmente disponibles.
Si también desea patrocinar una función (por ejemplo, el soporte de otro bug tracker) o si desea obtener más información sobre nuestro servicio de patrocinio, contáctenos.
Configuración de conexión
Crear configuración
No olvide habilitar la App correspondiente a su Bug Tracker. Luego, abra la configuración de su proyecto e ingrese información de conexión válida para crear una «configuración» de bug tracker:
- Nombre: identificará la conexión y se usará como etiqueta para las historias sincronizadas, por lo que debe ser única.
- Tipo: elige su bug tracker: Mantis BT, Bugzilla, Trac, Redmine o Jira.
- URL: la URL de su bug tracker.
- Nombre de usuario: el nombre de usuario de un usuario que tiene permisos suficientes en su bug tracker, de acuerdo con lo que desea hacer.
- Contrasenña: la contraseña de un usuario que tiene suficientes permisos en su bug tracker, de acuerdo con lo que desea hacer.
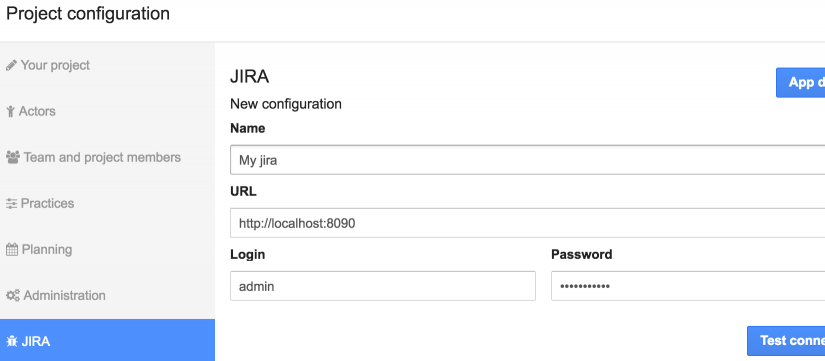
Luego, haga clic en «Probar conexión». Si la conexión falla, se mostrará un mensaje de error debajo, pero una mirada más cercana a los registros (icescrum.log y catalina.out) le dará más información sobre el problema.
Si la conexión tiene éxito, se mostrarán campos adicionales. Se buscarán proyectos remotos y tendrá que elegir el que desea integrar con su proyecto iceScrum (para Trac, solo hay un proyecto posible para una URL determinada).
No olvide hacer clic en «Crear» cuando haya terminado.
Actualizar o eliminar configuración
Puede actualizar la información de conexión en las configuraciones existentes.
Si desea detener todas las importaciones y sincronizaciones automáticas, puede deshabilitar la configuración o eliminarla.
Actualizar campos remotos
Para crear reglas de importación y sincronización, usará campos y valores que se obtienen del bug tracker. Se recuperan automáticamente en la primera conexión y se almacenan en caché en iceScrum. Si desea utilizar las últimas versiones de estos campos, haga clic en «Actualizar campos remotos».
Configuración de Bugzilla
Esta integración requiere un punto final XML-RPC en su servidor Bugzilla. Está habilitado por el módulo XMLRPC::Lite Bugzilla Perl (alternativamente, parece que Test::Taint podría hacer el trabajo).
Puede verificar que su servidor Bugzilla tenga el módulo XMLRPC::Lite Perl instalado marcando esta URL en su navegador: http://bugzilla.yourserver.com/xmlrpc.cgi, debería mostrar una página en blanco. También puede probar este comando cURL que devuelve la versión de su servidor Bugzilla:
curl http://bugzilla.yourserver.com/xmlrpc.cgi
-H "Content-Type: text/xml"
-d "<?xml version='1.0' encoding='UTF-8'?><methodCall><methodName>Bugzilla.version</methodName><params></params></methodCall>"
Si se devuelve un error, entonces hay un problema en su servidor Bugzilla, probablemente relacionado con módulos faltantes. Puede iniciar sesión como root en su servidor Bugzilla y verificar los módulos instalados:
./checksetup.pl --check-modules
Debería tener XMLRPC::Lite y todos los módulos necesarios instalados. Si no es el caso, aquí se explica cómo instalar un módulo (repetir para cada módulo requerido):
./install-module.pl XMLRPC::Lite
Luego verifique que esté correctamente instalado con:
./checksetup.pl --check_modules
Si falla una instalación, puede estar relacionada con una biblioteca de analizador XML faltante: XML::Parser. La instalación de este módulo a través de CPAN puede fallar, así que aquí es cómo puede instalarlo con apt-get (en los sistemas operativos basados en Debian):
sudo apt-get install libxml-parser-perl
Configuración de Trac
Esta integración requiere un punto final XML-RPC en su servidor Trac. Lo proporciona el plugin XML-RPC (ver http://trac-hacks.org/wiki/XmlRpcPlugin).
Puede instalar el complemento con el comando siguiente:
sudo easy_install -Z -U http://trac-hacks.org/svn/xmlrpcplugin/trunk
Luego, debe habilitarlo en su archivo de configuración trac.ini:
[components] tracrpc.* = enabled
Puede verificar que este plugin esté instalado correctamente al marcar esta URL en su navegador: http://yourTracServer.com/YourProject/rpc. Debería mostrar la documentación de la API RPC, incluyendo la versión de API. La integración de iceScrum requiere la versión de API 1.1.2 o superior (esta no es la versión de Trac). Esta página también muestra los permisos necesarios para cada acción.
El usuario de Trac utilizado por iceScrum debe tener los siguientes permisos (elija uno):
- either XML_RPC, TICKET_VIEW and TICKET_MODIFY,
- or XML_RPC and TICKET_ADMIN,
- or TRAC_ADMIN.
Los permisos pueden heredarse de grupos como «autenticado» o «anónimo».
Si usa el módulo de inicio de sesión del plugin AccountManager, lea las siguientes instrucciones:
Para usar la API XML-RPC, iceScrum necesita autenticarse a través de medios automáticos. El módulo de inicio de sesión de Trac HTTP predeterminado (trac.web.auth.loginmodule) permite la autenticación automática, mientras que el módulo de inicio de sesión de AccountManager HTML (acct_mgr.web_ui.loginmodule) no lo hace. Afortunadamente, el plugin HttpAuthPlugin plugin reinstala la autenticación HTTP en rutas específicas. Aquí están las instrucciones para usarlo:
1. Instala HttpAuthPlugin :
easy_install -Z -U http://trac-hacks.org/svn/httpauthplugin/trunk/
2. Habilite el plugin entrac.ini
[components] httpauth.* = enabled
3. Configure la ruta para la autenticación HTTP en trac.ini
[httpauth] paths = /login/xmlrpc
4. Configure Apache para que no separe la información de autorización (en httpd.conf):
WSGIPassAuthorization On
Configuración de Redmine
Con respecto a Redmine, solo tiene que habilitar los servicios web REST cuando inicie sesión con una cuenta de administrador, de la manera siguiente:
Administración> Configuración> Autenticación> Habilitar el servicio web REST
o Administración> Configuración> API> Habilitar el servicio web REST
El usuario de Redmine que iceScrum utilizará necesita los permisos «Guardar consultas», «Ver problemas» y «Editar problemas» en los proyectos que desee integrar. Si desea que iceScrum recupere campos personalizados o usuarios de Redmine, entonces el usuario deberá ser un administrador (esto puede parecer excesivo, pero Redmine parece requerirlo).
Tenga en cuenta que al crear la configuración, no obtendrá un error si ingresa credenciales incorrectas. En lugar de fallar, Redmine proporcionará la lista de proyectos públicos que están disponibles para usuarios anónimos. Por lo tanto, asegúrese de que los proyectos coincidan con los proyectos asociados al usuario iceScrum Redmine antes de guardar la configuración.
La URL de Redmine para utilizar en la configuración del bug tracker iceScrum es la URL base del servidor de Redmine, sin ningún recurso. Generalmente es la URL de la página de bienvenida de Redmine.
Configuración de Jira
API Jira REST
La API REST de Jira es requerida por esta integración. Debería estar habilitado por defecto en tu instancia de Jira.
Usuario Jira
El usuario de Jira que iceScrum utilizará necesita permisos suficientes según lo que desee hacer. Los usos básicos requieren explorar problemas y proyectos y problemas de actualización. La mayoría de los más avanzados requieren resolver problemas, cerrar problemas y cambiar el destinatario del problema y el reportero.
Al crear la configuración, si ingresa una contraseña incorrecta varias veces seguidas, la autenticación de este usuario a través de la API se desactivará y obtendrá un mensaje de error «403 prohibido». En tal caso, deberá autenticarse a través de la aplicación Jira e ingresar un CAPTCHA para volver a habilitar la autenticación API.
Transiciones
La API REST de Jira carece de soporte adecuado para las transiciones, por lo que nos disculpamos por las limitaciones que encontrará en esta integración.
Si desea obtener una buena lista de transiciones disponibles, entonces el usuario iceScrum Jira tendrá que ser un administrador. En este caso, se mostrarán todas las transiciones, agrupadas por flujo de trabajo, para todos los flujos de trabajo de su servidor Jira (porque Jira no proporciona ninguna forma de filtrar los flujos de trabajo asociados a un proyecto específico). De lo contrario, tendrá que ingresar el nombre de la transición a mano, que es más propenso a errores. En ambos casos, la transición se activará de acuerdo con su nombre y solo su nombre (no hay verificación de id. Técnica ni verificación de flujo de trabajo) por lo que debe coincidir con el nombre que se muestra en Jira cuando inicie sesión como el usuario iceScrum Jira (asegúrese de que use el mismo idioma).
Si las reglas de sincronización definidas en una historia dada para un estado dado incluyen una actualización de transición y si la transición está asociada con una pantalla, iceScrum automáticamente intentará completar la pantalla de acuerdo con las otras reglas. Las reglas restantes se ejecutarán a través de una actualización regular. Tenga en cuenta que las actualizaciones provistas con la transición pueden ser anuladas por Funciones de publicación definidas en la transición.
Los esquemas de flujo de trabajo permiten definir diferentes flujos de trabajo según el tipo de problema. Tenga cuidado al definir las reglas de transición: las transiciones deben estar disponibles para todos los tipos de problemas que serán importados en su configuración iceScrum Jira. Si tiene que administrar tipos de problemas que tienen flujos de trabajo diferentes, le recomendamos que cree una configuración Jira de iceScrum para cada tipo de problema.
Configuración de Mantis
Con respecto a Mantis, solo tiene que habilitar el modulo PHP: php-soap
Reglas de importación
Crear reglas de importación
Una vez que su conexión está configurada, puede crear reglas de importación para importar problemas desde su bug tracker a iceScrum. Se importarán como historias iceScrum.
Puede filtrar los problemas para importar según los campos remotos:
- Mantis BT:Filtro Mantis: un filtro que existe en Mantis. No puede crear múltiplas reglas de importación para el mismo filtro.
- Bugzilla: Componente, Estado.
- Trac: Componente, estado, tipo, resolución, prioridad, versión, hito. Si no elige ningún campo, se obtendrán todos los problemas.
- Redmine: Consulta: una consulta guardada en la cuenta de usuario de Redmine utilizada por iceScrum. No puede crear múltiplas reglas de importación para la misma consulta.
- Jira: Filtro: un filtro favorito guardado de una búsqueda en la cuenta Jira utilizada por iceScrum. No puede crear múltiplas reglas de importación para el mismo filtro.
Entonces puede personalizar las nuevas historias:
- Estado de las historias creadas: puede crear historias «sugeridas» que se incluyan en el area de ensayo e historias «aceptadas» que estén en la pila del producto. Los estados siguientes no son compatibles ya que dependen del flujo de trabajo iceScrum.
- Tipo de historias creadas: puede elegir «Historia de usuario», «Historia de defecto» o «Historia técnica».
- Associar con una característica: opcional.
- Tags de historias creadas: puede elegir tags para categorizar las historias (por ejemplo, dependiendo de la regla de importación) y encontrarlas fácilmente más tarde.
Finalmente, configure la importación:
- Frecuencia de extracción: Puede elegir de importar manualmente (ver explicación a continuación) o periódicamente (cada 1, 5, 15, 30 o 60 minutos).
- Permitir historias duplicadas de problemas: iceScrum permite crear nuevas historias para problemas que ya se han importado. Duplicados generalmente deben ser evitados.
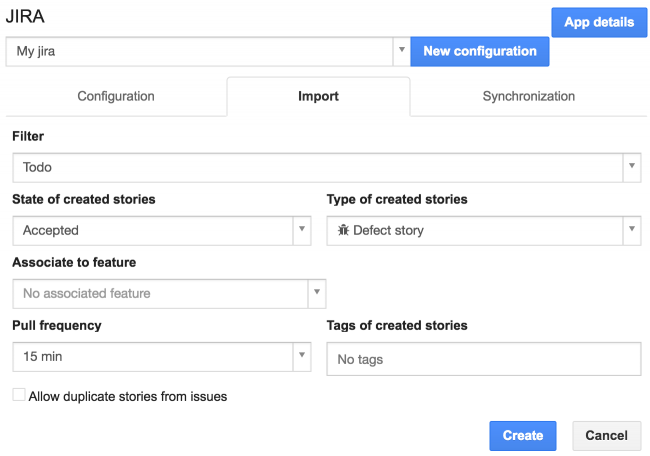
No olvide de hacer clic en «Crear». Puede crear tantas reglas de importación como sea necesario.
Las importaciones manuales se pueden desencadenar desde el Area de ensayo y la Pila del producto haciendo clic en el botón Actualizar en la barra de herramientas de estas Pilas. En el Area de ensayo, solo se activarán las reglas para las historias «sugeridas». En la Pila del producto, solo se activarán las reglas para las historias «Aceptadas».
Historias importadas
Las historias importadas se crean de acuerdo con los datos importados (los valores pueden truncarse para ajustarse a los campos iceScrum) y su configuración personalizada. Algunos campos reciben valores «especiales»:
- creador: lleno con el primer Propietario del Producto o Scrum Master encontrado en su equipo.
- tags: además de los tags personalizados, se agrega el nombre de la configuración (en mayúscula y sin espacios). Este tag se muestra en el resumen de configuración, haga clic en ello para mostrar todas sus historias importadas.
- origen: combina el nombre de la configuración y el ID del problema que materializan el vínculo entre la historia y el problema.
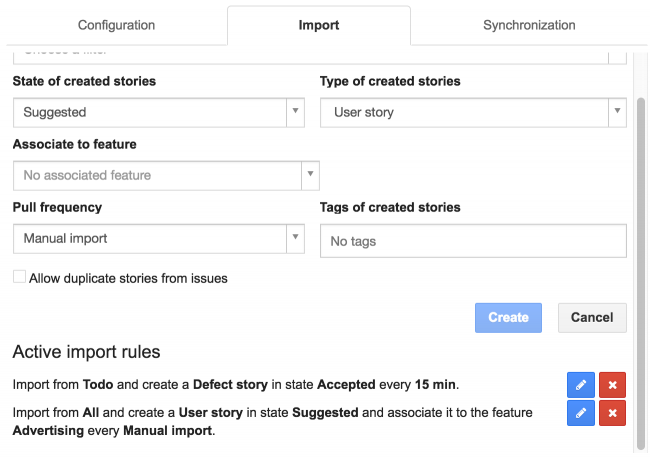
Actualizar o eliminar reglas de importación
Las reglas de importación se pueden actualizar o eliminar.
Reglas de sincronización
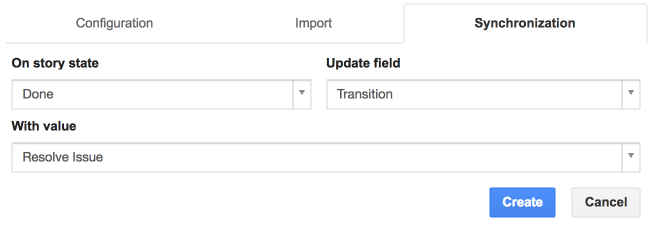
Crear reglas de sincronización
Cuando las historias importadas cambian de estado en iceScrum, puede actualizar automáticamente el problema correspondiente gracias a las reglas de sincronización. Solo las historias que se han importado de un bug tracker pueden desencadenar actualizaciones de problemas remotos a través del proceso de sincronización.
Primero, elija el estado que desencadena la actualización. Luego, elija el campo remoto para actualizar y su nuevo valor. Algunos valores de campo se recuperan de su bug tracker. Puede actualizarlos desde la pestaña «Configuración».
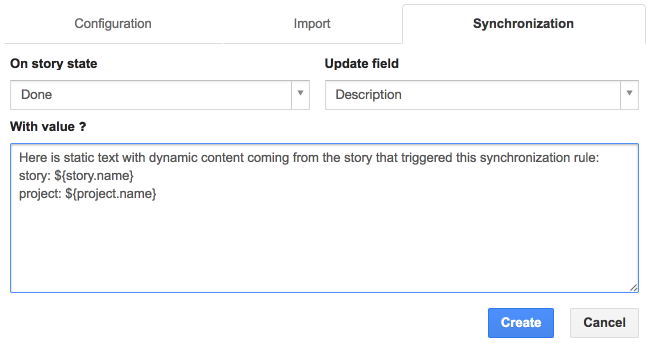
Para los campos de texto, puede ingresar una cadena con variables opcionales cuyo valor depende del contexto de la historia:
- historia: id, name, description, notes, origin, effort, rank, affectVersion, suggestedDate, acceptedDate, plannedDate, estimatedDate, inProgressDate, doneDate
- usuario: lastName, firstName, username, email
- proyecto: id, name, pkey, description, startDate, endDate
- entrega (para historias asociadas a una iteración): orderNumber, name, startDate, endDate
- iteración (para historias asociadas a una iteración): index, goal, velocity, plannedVelocity, deliveredVersion, startDate, endDate
Para usar estos valores dinámicos, envuélvalos en ${…}, p. ${story.name} … ${user.username}.
Actualice o elimine las reglas de sincronización
Se pueden actualizar o eliminar las reglas de sincronización.
Sincronizar al importar
Puede combinar reglas de importación y sincronización para crear ciclos de retroalimentación. Para hacerlo, defina las reglas de sincronización que se desencadenan por el estado establecido en las historias importadas.
Por ejemplo, defina una regla de importación que importe los problemas como historias aceptadas. Luego, defina una regla de sincronización que actualice el estado de un problema a «confirmado» cuando la historia sea «aceptada». La combinación de estas reglas actualizará el estado de cada problema a «confirmado» cuando se importe en iceScrum.
Dicha sincronización puede excluir problemas del filtro que se acaba de utilizar para importarlos.