Documentation Cette documentation ne s'applique qu'à iceScrum v7.
Pour un vieux serveur iceScrum R6, lisez la documentation correspondante ou migrez.
-
Installation ou Mise à jour
-
Démarrage
-
Fonctionnalités de base
Apps & intégrations
Neatro
Companion
MURAL
Microsoft Teams
Discord
iObeya
Zoom
Google Hangouts Meet
Jamboard by Google
Miro
Jitsi Meet
Mattermost
Custom project dashboard
Agile KPIs
Webhooks
Forecast
Agile fortune
SAML Authentication
Labels
Share
Zapier
Story workflow
FeatureMap
Temps passé
Diagrammes & mockups
Stories épiques
Portfolio
Project Roadmap
Mood
Toolbox
Authentification externe
Intégration continue
Fichiers attachés Cloud
Capacité de l’équipe
Bug trackers
LDAP / Active Directory
Slack
Administration du projet
Administration des utilisateurs
Administration du serveur
Git & SVN
Export de données
Import Excel
Responsable de tâche
Vote de stories
Modèle de story
Apps & intégrations
Backlogs personnalisés
-
Migration
-



Synchronisez automatiquement vos données de projet entre votre outil de suivi de bugs/tickets et iceScrum.
![]()
![]()
![]()
![]()
![]()

Cette intégration est bidirectionnelle : vous pouvez importer des problèmes à partir de votre bug tracker pour créer des stories iceScrum et vous pouvez aussi automatiquement mettre à jour les problèmes dans votre bug tracker lorsque les stories correspondantes sont mises à jour.
Principles
L’intégration avec des bug trackers est divisée en plusieurs Apps, une pour chaque bug tracker intégré avec iceScrum. La plupart du fonctionnement est le même pour chaque intégration, c’est pourquoi la documentation est unifiée.
Il y a 4 étapes pour définir l’intégration avec un bug tracker :
- Activer l’App,
- Configurez la connexion dans les paramètres de votre projet,
- Importer des problèmes grâce aux règles d’importation (bug tracker -> iceScrum),
- Mettez à jour les problèmes en fonction des mises à jour de la story grâce aux règles de synchronisation (iceScrum -> bug tracker).
Notez bien qu’il n’y a actuellement aucun moyen de mettre à jour ou de supprimer une story lorsque le problème correspondant est mis à jour ou fermé.
Les bug trackers actuellement disponibles sont :
- Mantis BT: 1.2.15 et au-dessus (2.x est supporté),
- Bugzilla: 3.6 et au-dessus avec le plugin XML-RPC installé , référez-vous à la section correspondante,
- Trac: 1.0.1 et au-dessus avec le plugin XML-RPC installé , référez-vous à la section correspondante,
- Redmine: 2.6.2 et au-dessus, référez-vous à la section correspondante.
- Jira: 6.2.7 et au-dessus, référez-vous à la section corrspondante.
- VSTS and TFS: Visual Studio Team Services et Team Foundation Server à partir de 2015, référez-vous à la section correspondante.
Nous avons développé cette intégration dans le cadre de notre service de sponsoring, qui permet aux entreprises de donner la priorité au développement d’une fonctionnalité de leur choix. Nous tenons d’ailleurs à remercier nos clients qui ont parrainé les intégrations actuellement disponibles.
Si vous souhaitez aussi sponsoriser une fonctionnalité (par exemple l’intégration d’un autre bug tracker) ou si vous souhaitez avoir plus d’informations sur notre service de sponsoring, contactez nous.
Configuration de connection
Créer une configuration
N’oubliez pas d’activer l’App correspondant à votre Bug Tracker. Ensuite, ouvrez les paramètres de votre projet et entrez des informations de connexion valides pour créer une « configuration » de bug tracker :
- Nom: identifiera la connexion et sera utilisé comme balise pour les stories synchronisées, il doit donc être unique.
- Type: choisissez votre bug tracker: Mantisbt, Bugzilla, Trac, Redmine, Jira ou VSTS.
- URL: l’URL de votre bug tracker.
- Login: le nom d’un utilisateur ayant des autorisations suffisantes sur votre bug tracker, selon ce que vous voulez faire.
- Mot de passe: le mot de passe d’un utilisateur ayant des permissions suffisantes sur votre bug tracker, selon ce que vous voulez faire.
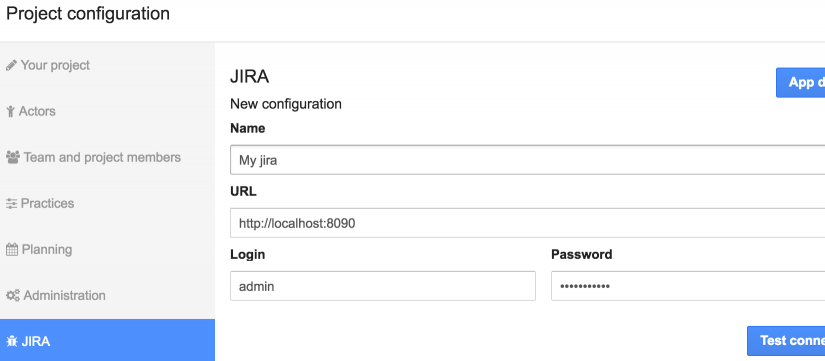
Ensuite, cliquez sur « Tester la connexion ». Si la connexion échoue, un message d’erreur s’affichera en dessous et un examen plus approfondi des logs (icescrum.log et catalina.out) vous donnera plus d’informations sur le problème.
Si la connexion réussit, des champs supplémentaires seront affichés. Les projets distants seront récupérés et vous devrez choisir celui que vous voulez intégrer dans votre projet iceScrum (pour Trac, il n’y a qu’un seul projet possible pour une URL donnée).
N’oubliez pas de cliquer sur « Créer » lorsque vous avez terminé.
Mettre à jour ou supprimer la configuration
Vous pouvez mettre à jour les informations de connexion sur les configurations existantes.
Si vous souhaitez arrêter toutes les importations et synchronisations automatiques, vous pouvez désactiver la configuration ou la supprimer.
Refresh remote fields
Afin de créer des règles d’importation et de synchronisation, vous utiliserez les champs et les valeurs extraits du bug tracker. Ils sont automatiquement récupérés lors de la première connexion et mis en cache dans iceScrum. Si vous souhaitez utiliser les dernières versions de ces champs, cliquez sur « Actualiser les champs distants ».
Configuration Bugzilla
Cette intégration nécessite un point de terminaison XML-RPC sur votre serveur Bugzilla. Il est activé par le module XMLRPC :: Lite Bugzilla Perl (alternativement, il semble que Test :: Taint pourrait convenir).
Vous pouvez vérifier que le module XMLRPC::Lite Perl est installé sur votre serveur Bugzilla en cochant cette URL dans votre navigateur: http://bugzilla.yourserver.com/xmlrpc.cgi, il devrait afficher une page vierge. Vous pouvez également essayer cette commande cURL qui renvoie la version de votre serveur Bugzilla:
curl http://bugzilla.yourserver.com/xmlrpc.cgi
-H "Content-Type: text/xml"
-d "<?xml version='1.0' encoding='UTF-8'?><methodCall><methodName>Bugzilla.version</methodName><params></params></methodCall>"
Si une erreur est renvoyée, c’est qu’il y a un problème sur votre serveur Bugzilla, probablement lié à des modules manquants. Vous pouvez vous connecter en tant que root sur votre serveur Bugzilla et vérifier les modules installés :
./checksetup.pl --check-modules
Vous devez avoir XMLRPC::Lite et tous les modules requis installés. Si ce n’est pas le cas, voici comment installer un module (répétez pour chaque module requis):
./install-module.pl XMLRPC::Lite
Vérifiez ensuite qu’il est correctement installé avec :
./checksetup.pl --check_modules
Si une installation échoue, cela peut être lié à une bibliothèque d’analyseurs XML manquante: XML::Parser. L’installation de ce module via CPAN peut échouer. Voici comment vous pouvez l’installer avec apt-get (sur les systèmes d’exploitation Debian) :
sudo apt-get install libxml-parser-perl
Configuration Trac
Cette intégration nécessite un point de terminaison XML-RPC sur votre serveur Trac. Il est fourni par le plugin XML-RPC (voir http://trac-hacks.org/wiki/XmlRpcPlugin).
Vous pouvez installer le plugin avec la commande suivante:
sudo easy_install -Z -U http://trac-hacks.org/svn/xmlrpcplugin/trunk
Vous devez ensuite l’activer dans votre fichier de configuration trac.ini :
[components] tracrpc.* = enabled
Vous pouvez vérifier que ce plugin est correctement installé en cochant cette URL dans votre navigateur :
http://yourTracServer.com/YourProject/rpc. Il devrait afficher la documentation de l’API RPC, y compris la version de l’API. L’intégration iceScrum nécessite la version 1.1.2 de l’API ou supérieure (ce n’est pas la version Trac). Cette page affiche également les autorisations requises pour chaque action.
L’utilisateur Trac utilisé par iceScrum doit avoir les permissions suivantes (choisissez-en une):
- soit XML_RPC, TICKET_VIEW et TICKET_MODIFY,
- ou XML_RPC et TICKET_ADMIN,
- ou TRAC_ADMIN.
Les autorisations peuvent être héritées de groupes « authentifié » ou « anonyme ».
Si vous utilisez le module de connexion du plugin AccountManager, lisez les instructions suivantes:
Pour utiliser l’API XML-RPC, iceScrum doit s’authentifier par des moyens automatiques. Le module de connexion HTTP Trac par défaut ( trac.web.auth.loginmodule ) permet l’authentification automatique, contrairement au module de connexion HTML AccountManager ( acct_mgr.web_ui.loginmodule ).
Heureusement, le plugin HttpAuthPlugin réinstalle l’authentification HTTP sur des chemins spécifiques. Voici les instructions pour l’utiliser:
1. Installez HttpAuthPlugin :
easy_install -Z -U http://trac-hacks.org/svn/httpauthplugin/trunk/
2. Activez le plugin dans trac.ini
[components] httpauth.* = enabled
3. Configurez le chemin pour l’authentification HTTP dans trac.ini
[httpauth] paths = /login/xmlrpc
4. Configurez Apache pour qu’il ne dépouille pas les informations d’autorisation (dans httpd.conf) :
WSGIPassAuthorization On
Configuration Redmine
Concernant Redmine, vous devez uniquement activer les services Web REST lorsque vous êtes connecté avec un compte d’administrateur, comme suit:
Administration> Configuration> Authentification> Activer l’API REST
ou Administration> Configuration> API> Activer l’API REST
L’utilisateur de Redmine qui sera utilisé par iceScrum a besoin des permissions « Enregistrer les requêtes » « Afficher les problèmes » et « Modifier les problèmes » sur les projets que vous souhaitez intégrer. Si vous voulez qu’iceScrum récupère des champs personnalisés ou des utilisateurs de Redmine, alors l’utilisateur devra être un administrateur (cela peut sembler exagéré mais Redmine semble l’exiger).
Veuillez noter que lors de la création de la configuration, vous n’obtiendrez pas d’erreur si vous entrez des informations d’identification incorrectes. Au lieu d’échouer, Redmine fournira la liste des projets publics disponibles pour les utilisateurs anonymes. Ainsi, assurez-vous que les projets correspondent aux projets associés à l’utilisateur iceScrum Redmine avant d’enregistrer la configuration.
L’URL de Redmine à utiliser dans la configuration bug tracker d’iceScrum est l’URL de base du server Redmine, sans aucune ressource dans l’URL. C’est généralement l’URL de la page d’accueil Redmine.
Configuration Jira
API REST Jira
L’API REST Jira est requise pour cette intégration. Elle devrait être activée par défaut sur votre instance Jira.
Utilisateur Jira
L’utilisateur Jira qui sera utilisé par iceScrum a besoin d’autorisations suffisantes en fonction de ce que vous voulez faire. Les utilisations de base nécessitent de parcourir les projets et les problèmes ainsi que les mise à jour des problèmes. Les utilisation plus avancées nécessitent la résolution des problèmes, leur fermeture et la modification du destinataire et du rapporteur.
Lors de la création de la configuration, si vous entrez un mot de passe incorrect plusieurs fois de suite, l’authentification de cet utilisateur via l’API sera désactivée et vous obtiendrez un message d’erreur « 403 interdit ». Dans ce cas, vous devrez vous authentifier via l’application Jira et entrer un CAPTCHA pour réactiver l’authentification de l’API.
Transitions
L’API REST de Jira ne dispose pas d’un support approprié pour les transitions, nous nous excusons donc pour les limitations que vous rencontrerez dans cette intégration.
Si vous souhaitez obtenir une belle liste des transitions disponibles, l’utilisateur iceScrum Jira devra être administrateur. Dans ce cas, toutes les transitions seront affichées, regroupées par workflow, pour tous les workflows de votre serveur Jira (car Jira ne permet pas de filtrer les workflows associés à un projet spécifique). Sinon, vous devrez entrer manuellement le nom de la transition, ce qui est plus sujet aux erreurs. Dans les deux cas, la transition sera déclenchée en fonction de son nom uniquement (il n’y a pas de vérification d’identification technique ni d’identification de workflow). Elle doit donc correspondre au nom affiché dans Jira lorsqu’elle est connectée en tant qu’utilisateur iceScrum Jira. (assurez-vous de bien utiliser le même language).
Si les règles de synchronisation définies sur une story donnée pour un état donné incluent une mise à jour de transition et si la transition est associée à un écran, iceScrum essayera automatiquement de compléter l’écran selon les autres règles. Les règles restantes seront exécutées via une mise à jour régulière. Veuillez noter que les mises à jour fournies avec la transition peuvent être annulées par les Fonctions Métier définies lors de la transition.
Les schémas de workflow permettent de définir différents workflows en fonction du type de problème. Soyez prudent lors de la définition des règles de transition : les transitions doivent être disponibles pour tous les types de problèmes qui seront importés dans votre configuration iceScrum Jira. Si vous devez gérer des types de problèmes ayant des workflows différents, nous vous recommandons de créer une configuration iceScrum Jira pour chaque type de problème.
Configuration Visual Studio Team Service
- VSTS work items : Créez des stories dans iceScrum depuis les work items VSTS.
- VSTS CI : Liez vos builds VSTS avec iceScrum.
- VSTS code : Liez vos commits VSTS à vos tâches iceScrum.
Authentification
Pour authentifier iceScrum dans VSTS, vous devez générer un Personal Access Token (PAT).
La documentation microsoft officielle explique comment l’obtenir.
Ce Personal Access Token expire après un temps défini. Pensez à mettre un rappel dans votre calendrier d’équipe pour le changer avant qu’il n’expire.
Les scopes requis du Personal Access Token sont :
- Project and team (read)
- Work item search (read)
- Work items (read and write)
Connexion depuis iceScrum
Dans le dialogue de connexion iceScrum
- Url: https://mondomaine.visualstudio.com, remplacez par votre domaine.
- Login : Le compte avec lequel vous avez généré le personal access token
- Password : Le personal access token
Importer des user stories avec des queries VSTS
Les queries pour importer des user stories dans iceScrum sont directement issues de votre projet VSTS. La configuration la plus commune revient à importer les stories au status « New » dans VSTS vers des user stories iceScrum au status « Suggérée ». Pour cela vous aurez besoin d’une query VSTS pour les nouvelles user stories. Vous pouvez ajouter des queries dans VSTS depuis l’onglet « Work » de votre projet. Les queries créées ici seront automatiquement disponibles dans les filtres d’import iceScrum.
Nous recommandons d’utiliser uniquement des queries « flat » pour importer des users stories ou des backlog items de VSTS. Cependant iceScrum est capable d’importer tout les types de work items de VSTS sous forme de user stories.
Configuration Mantis
Concernant Mantis, vous devez activer le module php suivant : php-soap si celui n’est pas actif.
Règles d'import
Créer des règles d'import
Une fois votre connexion établie, vous pouvez créer des règles d’importation afin d’importer les bugs depuis votre bug tracker dans iceScrum. Ils seront importés comme des stories iceScrum.
Vous pouvez filtrer les problèmes à importer en fonction des champs distants :
- Mantis BT : Filtre Mantis: un filtre existant dans Mantis. Vous ne pouvez pas créer plusieurs règles d’importation pour le même filtre.
- Bugzilla : Composant, Statut.
- Trac : Composant, Statut, Type, Résolution, Priorité, Version, Jalon. Si vous ne choisissez aucun champ, tous les problèmes seront récupérés.
- Redmine : Requête : une requête enregistrée sur le compte utilisateur Redmine utilisé par iceScrum. Vous ne pouvez pas créer plusieurs règles d’importation pour la même requête.
- Jira : Filtre : un filtre favori enregistré à partir d’une recherche sur le compte Jira utilisé par iceScrum. Vous ne pouvez pas créer plusieurs règles d’importation pour le même filtre.
- VSTS : Query : une query enregistrée sur le compte VSTS utilisé par iceScrum. Vous ne pouvez pas créer plusieurs règles d’importation pour la même query.
Vous pouvez ensuite personnaliser les nouvelles stories :
- Etat des stories crées : vous pouvez créer des stories « Suggérées » qui iront dans le bac à sable et d’autres « Acceptées » qui iront dans le backlog. Les états suivants ne sont pas supportés car ils s’appuient sur le workflow d’iceScrum.
- Type de stories créées : vous pouvez choisir « Story d’utilisateur », « Story de défaut » ou « Story technique ».
- Associées à une feature : optionnel.
- Tags des stories créées : vous pouvez choisir des tags pour catégoriser vos stories (par exemple en fonction des règles d’importation) afin de les retrouver plus facilement par la suite.
Enfin, configurez l’import:
- Fréquence de récupération : vous pouvez choisir un import manuel (voir les explications plus bas) ou périodique (toutes les 1, 5, 15, 30 ou 60 minutes).
- Autoriser les doublons de stories pour un même problème : iceScrum doit-il créer de nouvelles stories pour les problèmes qui ont déjà été importés. Généralement les doublons doivent être évités.
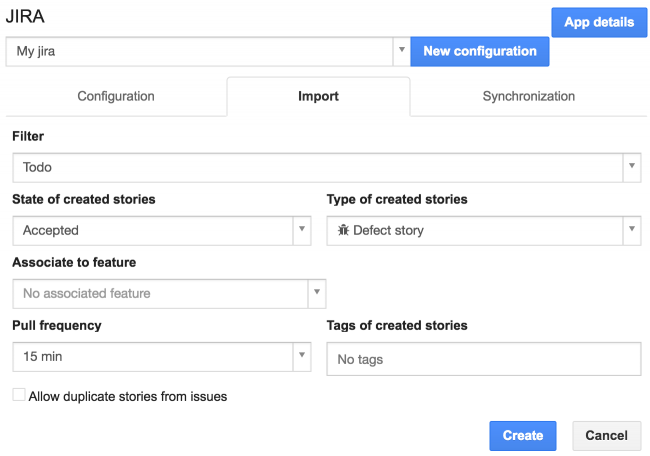
N’oubliez pas de cliquer sur « Créer ». Vous pouvez créer autant de règles d’importation que nécessaire.
Les importations manuelles peuvent être déclenchées depuis le Bac à sable et le Backlog en cliquant sur le bouton d’actualisation dans la barre d’outils de ces Backlogs. Dans le Bac à sable, seules les règles pour les stories « suggérées » seront déclenchées. Dans le Backlog, seules les règles pour les stories « Acceptées » seront déclenchées.
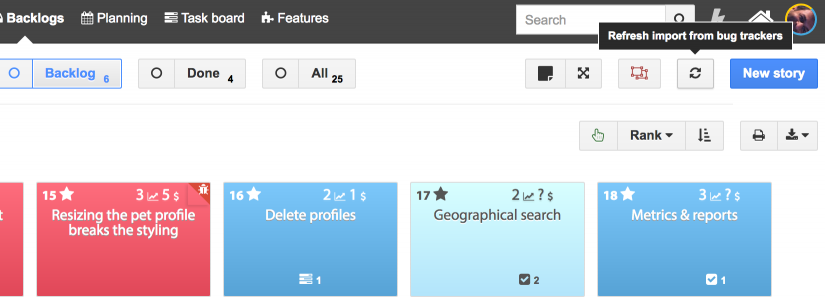
Stories importées
Les stories importées sont créés en fonction des données de problèmes importées (les valeurs peuvent être tronquées pour s’adapter aux champs iceScrum) et de votre configuration personnalisée. Certains champs reçoivent des valeurs « spéciales » :
- créateur : rempli avec le premier Product Owner ou Scrum Master trouvé dans votre équipe.
- tags : en plus des tags personnalisés, le nom de la configuration est ajouté (en majuscules et sans espaces). Ce tag est affiché dans le récapitulatif de la configuration, cliquez dessus pour afficher toutes les stories importées.
- origine : combine le nom de la configuration et l’ID du problème qui matérialise le lien entre la story et le problème.
Mettre à jour ou supprimer les règles d'import
Les règles d’import peuvent être mise à jour ou supprimées.
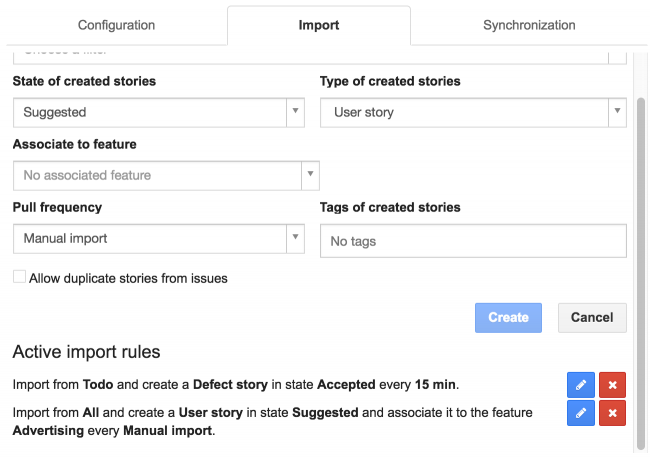
Règles de synchronisation
Créer des règles de synchronisation
Lorsque les stories importées changent d’état dans iceScrum, vous pouvez automatiquement mettre à jour le problème correspondant grâce aux règles de synchronisation. Seules les stories qui ont été importées à partir d’un bug tracker peuvent déclencher des mises à jour des problèmes distants via le processus de synchronisation.
D’abord, choisissez l’état qui déclenche la mise à jour. Ensuite, choisissez le champ distant à mettre à jour et sa nouvelle valeur. Certaines valeurs de champs sont récupérées depuis votre bug tracker. Vous pouvez les actualiser à partir de l’onglet « Configuration ».
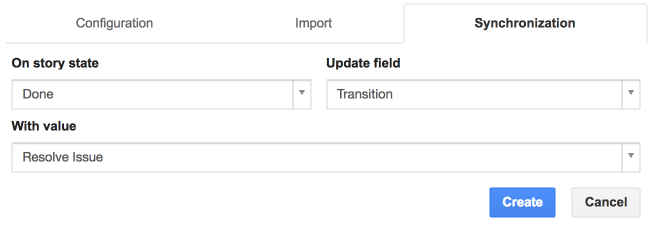
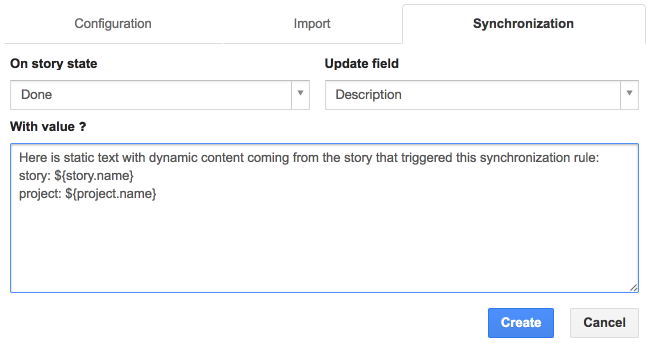
Pour les champs textuels, vous pouvez entrer une chaîne avec des variables optionnelles dont la valeur dépend du contexte de la story :
- story: id, name, description, notes, origin, effort, rank, affectVersion, suggestedDate, acceptedDate, plannedDate, estimatedDate, inProgressDate, doneDate
- utilisateur: lastName, firstName, username, email
- projet: id, name, pkey, description, startDate, endDate
- release (pour les stories associées a un sprint): orderNumber, name, startDate, endDate
- sprint (pour les stories associées a un sprint): index, goal, velocity, plannedVelocity, deliveredVersion, startDate, endDate
Pour utiliser ces valeurs dynamiques, entourez-les par ${…}, e.g. ${story.name} … ${user.username}.
Mettre à jour ou supprimer les règles de synchronisation
Les règles de synchronisation peuvent être mise à jour ou supprimées.
Synchronisation à l'import
Vous pouvez combiner des règles d’importation et de synchronisation afin de créer des boucles de feedback. Pour ce faire, définissez les règles de synchronisation déclenchées par l’état défini sur les stories importées.
Par exemple, définissez une règle d’importation qui importe les problèmes en tant que stories acceptées. Définissez ensuite une règle de synchronisation qui met à jour le statut d’un problème sur « confirmé » lorsque la story est « acceptée ». La combinaison de ces règles mettra à jour le statut de chaque problème à « confirmé » quand il est importé dans iceScrum.
Une telle synchronisation peut exclure des problèmes du filtre qui vient d’être utilisé pour les importer.